
Revisiting Layer-Adaptive Sparsity in KV Cache Compression
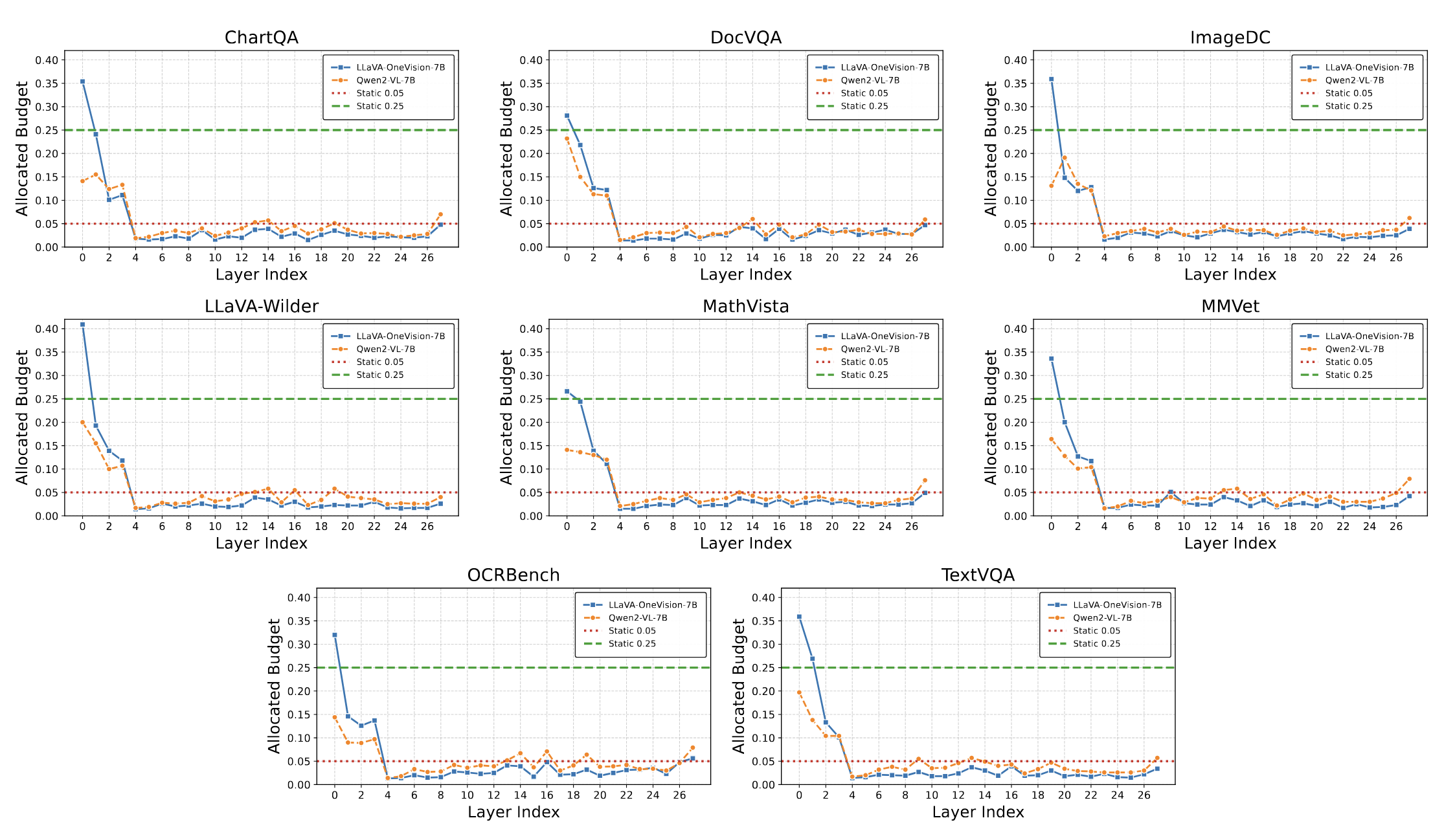
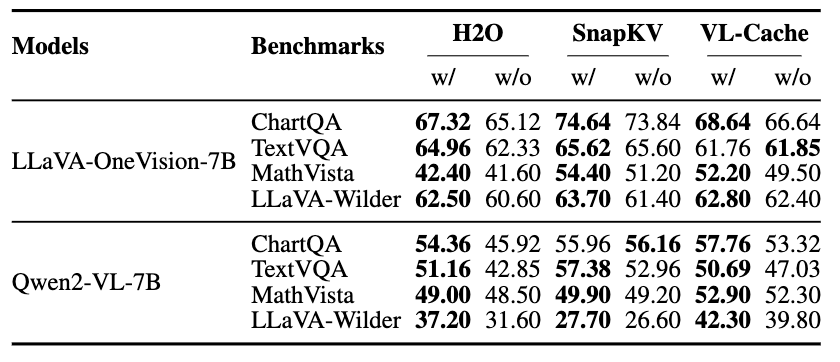
While layer-adaptive sparsity can benefit LLMs, our findings suggest it's not universally advantageous for LVLMs, especially at low sparsity budgets. For instance, VL-Cache's aggressive front-loading of budget to early layers can starve subsequent layers. A hybrid allocation (e.g., 80% uniform + 20% adaptive) showed improved performance.
Revisiting Head-Adaptive Mechanism in KV Cache Compression
Allowing different heads within the same layer to select cache tokens adaptively (head-adaptive) generally improves performance under aggressive budget constraints (e.g., 1% budget) by retaining more critical information.
Attention Sink Tokens in LVLMs
Attention sink tokens (tokens that receive high attention regardless of semantic relevance) are present in both text and image modalities in LVLMs. Removing these can degrade performance. Methods like StreamingLLM that preserve text sink tokens show improvements. Visual sink tokens also significantly impact performance; text-guided visual token pruning (e.g., FastV) may fail to capture these crucial visual sink tokens, unlike image-guided pruning (e.g., VisionZip).
Merging Strategies for Evicted Tokens
Merging evicted tokens can help recover information. However, cross-modal merging (e.g., visual tokens into text tokens) can disrupt critical textual features, especially at very low budgets, leading to performance degradation as seen with LOOK-M. Modality-specific merging (merging evicted tokens only within the same modality) shows improved performance.